Note: this is a translation of an older blog post written in French: Le problème « P est-il égal à NP ? ».
All right, I think I explained enough algorithmic complexity (part 1 and part 2) to start with a nice piece, which is to explain what is behind the “Is P equal to NP?” question – also called “P vs NP” problem.
The “P vs NP” problem is one of the most famous open problems, if not the most famous. It’s also part of the Millenium Prize problems, a series of 7 problems stated in 2000: anyone solving one of these problems gets awarded one million dollars. Only one of these problems has been solved, the Poincaré conjecture, proven by Grigori Perelman. He was awarded the Fields medal (roughly equivalent to a Nobel Prize in mathematics) for it, as well as the aforementioned million dollars; he declined both.
But enough history, let’s get into it. P and NP are called “complexity classes”. A complexity class is a set of problems that have common properties. We consider problems (for instance “can I go from point A to point B in my graph with 15 steps or less?”) and to put them in little boxes depending on their properties, in particularity their worst case time complexity (how much time do I need to solve them) and their worst case space complexity (how much memory do I need to solve them).
I explained in the algorithmic complexity blog posts what it meant for an algorithm to run in a given time. Saying that a problem can be/is solved in a given time means that we know how to solve it in that time, which means we have an algorithm that runs in that time and returns the correct solution. To go back to my previous examples, we saw that it was possible to sort a set of elements (books, or other elements) in time 
A polynomial time algorithm is an algorithm that finishes with a number of steps that is less than 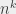


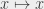
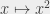



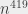

Now, I need to explain the difference between a problem and an instance of a problem – because I kind of need that level of precision 🙂 A problem regroups all the instances of a problem. If I say “I want to sort my bookshelf”, it’s an instance of the problem “I want to sort an arbitrary bookshelf”. If I’m looking at the length shortest path between two points on a given graph (for example a subway map), it’s an instance of the problem “length of shortest path in a graph”, where we consider all arbitrary graphs of arbitrary size. The problem is the “general concept”, the instance is a “concrete example of the general problem”.
The complexity class P contains all the “decision” problems that can be solved in polynomial time. A decision problem is a problem that can be answered by yes or no. It can seem like a huge restriction: in practice, there are sometimes way to massage the problem so that it can get in that category. Instead of asking for “the length of the shortest path” (asking for the value), I can ask if there is “a path of length less than X” and test that on various X values until I have an answer. If I can do that in a polynomial number of queries (and I can do that for the shortest path question), and if the decision problem can be solved in polynomial time, then the corresponding “value” problem can also be solved in polynomial time. As for an instance of that shortest path decision problem, it can be “considering the map of the Parisian subway, is there a path going from La Motte Piquet Grenelle to Belleville that goes through less than 20 stations?” (the answer is yes) or “in less than 10 stations?” (I think the answer is no).
Let me give another type of a decision problem: graph colorability. I like these kind of examples because I can make some drawings and they are quite easy to explain. Pick a graph, that is to say a bunch of points (vertices) connected by lines (edges). We want to color the vertices with a “proper coloring”: a coloring such that two vertices that are connected by a single edge do not have the same color. The graph colorability problems are problems such as “can I properly color this graph with 2, 3, 5, 12 colors?”. The “value” problem associated to the decision problem is to ask what is the minimum number of colors that I need to color the graph under these constraints.
Let’s go for a few examples – instances of the problem 🙂
A “triangle” graph (three vertices connected with three edges) cannot be colored with only two colors, I need three:
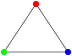
On the other hand, a “square-shaped” graph (four vertices connected as a square by four edges) can be colored with two colors only:

There are graphs with a very large number of vertices and edges that can be colored with only two colors, as long as they follow that type of structure:
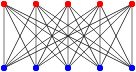
And I can have graphs that require a very large number of colors (one per vertex!) if all the vertices are connected to one another, like this:
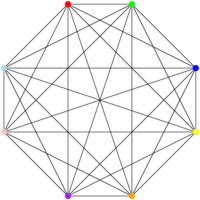
And this is where it becomes interesting. We know how to answer in polynomial time (where
I claim that this algorithm is running in polynomial time: why is that the case? The algorithm is, roughly, traversing all the vertices in a certain order and coloring them as it goes; the vertices are only visited once; before coloring a vertex, we check against all of its neighbors, which in the worst case all the other vertices. I hope you can convince yourself that, if we do at most 

Now, for the question “Can this graph be colored with three colors?”, well… nobody has yet found a polynomial algorithm that allows us to answer the question for any instance of the problem, that is to say for any graph. And, for reasons I’ll explain in a future post, if you find a (correct!) algorithm that allows to answer that question in polynomial time, there’s a fair chance that you get famous, that you get some hate from the cryptography people, and that you win one million dollars. Interesting, isn’t it?
The other interesting thing is that, if I give you a graph that is already colored, and that I tell you “I colored this graph with three colors”, you can check, in polynomial time, that I’m not trying to scam you. You just look at all the edges one after the other and you check that both vertices of the edge are colored with different colors, and you check that there are only three colors on the graph. Easy. And polynomial.
That type of “easily checkable” problems is the NP complexity class. Without giving the formal definition, here’s the idea: a decision problem is in the NP complexity class if, for all instances for which I can answer “yes”, there exists a “proof” that allows me to check that “yes” in polynomial time. This “proof” allows me to answer “I bet you can’t!” by “well, see, I can color that way, it works, that proves that I can do that with three colors” – that is, if the graph is indeed colorable with 3 colors. Note here that I’m not saying anything about how to get that proof – just that if I have it, I can check that it is correct. I also do not say anything about what happens when the instance cannot be colored with three colors. One of the reasons is that it’s often more difficult to prove that something is impossible than to prove that it is possible. I can prove that something is possible by doing it; if I can’t manage to do something, it only proves that I can’t do it (but maybe someone else could).
To summarize:
- P is the set of decision problems for which I can answer “yes” or “no” in polynomial time for all instances
- NP is the set of decision problems for which, for each “yes” instance, I can get convinced in polynomial time that it is indeed the case if someone provides me with a proof that it is the case.
The next remark is that problems that are in P are also in NP, because if I can answer myself “yes” or “no” in polynomial time, then I can get convinced in polynomial time that the answer is “yes” if it is the case (I just have to run the polynomial time algorithm that answers “yes” or “no”, and to check that it answers “yes”).
The (literally) one-million-dollar question is to know whether all the problems that are in NP are also in P. Informally, does “I can see easily (i.e. in polynomial time) that a problem has a ‘yes’ answer, if I’m provided with the proof” also mean that “I can easily solve that problem”? If that is the case, then all the problems of NP are in P, and since all the problems of P are already in NP, then the P and NP classes contain exactly the same problems, which means that P = NP. If it’s not the case, then there are problems of NP that are not in P, and so P ≠ NP.
The vast majority of maths people think that P ≠ NP, but nobody managed to prove that yet – and many people try.
It would be very, very, very surprising for all these people if someone proved that P = NP. It would probably have pretty big consequences, because that would mean that we have a chance to solve problems that we currently consider as “hard” in “acceptable” times. A fair amount of the current cryptographic operations is based on the fact, not that it is “impossible” to do some operations, but that it’s “hard” to do them, that is to say that we do not know a fast algorithm to do them. In the optimistic case, proving that P = NP would probably not break everything immediately (because it would probably be fairly difficult to apply and that would take time), but we may want to hurry finding a solution. There are a few crypto things that do not rely on the hypothesis that P ≠ NP, so all is not lost either 😉
And the last fun thing is that, to prove that P = NP, it is enough to find a polynomial time algorithm for one of the “NP-hard” problems – of which I’ll talk in a future post, because this one is starting to be quite long. The colorability with three colors is one of these NP-hard problems.
I personally find utterly fascinating that a problem which is so “easy” to get an idea about have such large implications when it comes to its resolution. And I hope that, after you read what I just wrote, you can at least understand, if not share, my fascination 🙂

One thought on “The “P vs NP” problem”