Note: this is the translation of a post that was originally published in French: Introduction à la complexité algorithmique – 2/2.
In the previous episode, I explained two ways to sort books, and I counted the elementary operations I needed to do that, and I estimated the number of operations depending on the number of books that I wanted to sort. In particular, I looked into the best case, worst case and average case for the algorithms, depending on the initial ordering of the input. In this post, I’ll say a bit more about best/worst/average case, and then I’ll refine the notion of algorithmic complexity itself.
The “best case” is typically analyzed the least, because it rarely happens (thank you, Murphy’s Law.) It still gives bounds of what is achievable, and it gives a hint on whether it’s useful to modify the input to get the best case more often.
The “worst case” is the only one that gives guarantees. Saying that my algorithm, in the worst case, executes in a given amount of time, guarantees that it will never take longer – although it can be faster. That type of guarantees is sometimes necessary. In particular, it allows to answer the question of what happens if an “adversary” provides the input, in a way that will make the algorithm’s life as difficult as possible – a question that would interest cryptographers and security people for example. Having guarantees on the worst case means that the algorithm works as desired, even if an adversary tries to make its life as miserable as possible. The drawback of using the worst case analysis is that the “usual” execution time often gets overestimated, and sometimes gets overestimated by a lot.
Looking at the “average case” gives an idea of what happens “normally”. It also gives an idea about what happens if the algorithm is repeated several times on independent data, where both the worst case and the best case can happen. Moreover, there is sometimes ways to avoid the worst cases, so the average case would be more useful in that case. For example, if an adversary gives me the books in an order that makes my algorithm slow, I can compensate that by shuffling the books at the beginning so that the probability of being in a bad case is low (and does not depend on my adversary’s input). The drawback of using the average case analysis is that we lose the guarantee that we have on the worst case analysis.
For my book sorting algorithms, my conclusions were as follows:
- For the first sorting algorithm, where I was searching at each step for a place to put the book by scanning all the books that I had inserted so far, I had, in the best case,
operations, in the worst case,
operations, and in the average case,
. operations.
- For the second sorting algorithm, where I was grouping book groups two by two, I had, in all cases,
operations.
I’m going to draw a figure, because figures are pretty. If the colors are not that clear, the plotted functions and their captions are in the same order.
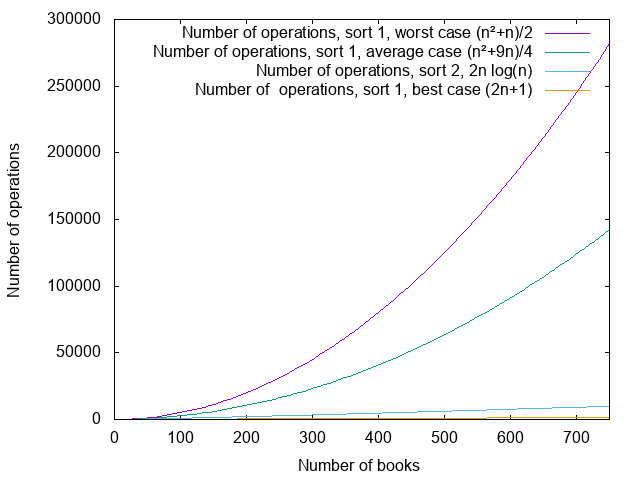
It turns out that, when talking about complexity, these formulas (


This may seem very imprecise, and I’ll admit that the first time I saw this kind of approximations, I was quite irritated. (It was in physics class, so I may not have been in the best of moods either.) Since then, I find it quite handy, and even that it makes sense. The fact that “it makes sense” has a strong mathematical justification. For the people who want some precision, and who are not afraid of things like “limit when x tends to infinity of blah blah”, it’s explained there: http://en.wikipedia.org/wiki/Big_O_notation. It’s vastly above the level of the post I’m currently writing, but I still want to justify a couple of things; be warned that everything that follows is going to be highly non-rigorous.
The first question is what happens to smaller elements of the formulas. The idea is that only keep what “matters” when looking at how the number of operations increases with the number of elements to sort. For example, if I want to sort 750 books, with the “average” case of the first algorithm, I have 


The second question is more complicated: why do I consider as identical 
To reduce the time that it takes an algorithm to execute, I have two possibilities. Either I reduce the time that each operation takes, or I reduce the number of operations. Suppose that I have a computer that can execute one operation by second, and that I want to sort 100 elements. The first algorithm, which needs 

That’s the idea behind removing the “multiplying numbers” when estimating complexity. Given an algorithm with a complexity “
So when I compare two algorithms, it’s much more interesting to see that one needs “something like
Of course, if two algorithms need “something along the lines of
Everything that I talked about so far is function of
The “constant time algorithms” and “logarithmic time algorithms” (whose numbers of operations are, respectively, a constant that does not depend on 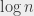
We’re also very happy when we find a “linear time algorithm” (the number of operations is “something like
We start grumbling a bit at 




In the real life, however, this type of reasoning does have its limits. When writing code, if there is a solution that takes 20 times (or even 2 times) less operations than another, it will generally be the one that we choose to implement. And the asymptotic behavior is only that: asymptotic. It may not apply for the size of the inputs that are processed by our code.
There is an example I like a lot, and I hope you’ll like it too. Consider the problem of multiplying matrices. (For people who never saw matrices: they’re essentially tables of numbers, and you can define how to multiply these tables of numbers. It’s a bit more complicated/complex than multiplying numbers one by one, but not that much more complicated.) (Says the girl who didn’t know how to multiply two matrices before her third year of engineering school, but that’s another story.)
The algorithm that we learn in school allows to multiply to matrices of size 

And this funny anecdote concludes this post. I hope it was understandable – don’t hesitate to ask questions or make comments 🙂

3 thoughts on “Introduction to algorithmic complexity – 2/2”