Ce billet a été traduit de sa version originale en français : Probabilités – Partie 2.
After the previous post about probability theory, here’s the second part, in which I’ll talk about random variables.
The idea of random variables is to have some way of dealing with events for which we do not exactly what happens (for instance, we roll a die), but still want to have some idea of what can happen. The die example is pretty simple, so using random variables may be a bit overkill, but let’s keep examples simple for now.
For a given experiment, we consider a variable, called  , and look at all the values it can reach with the associated probability. If my experiment is “rolling a die and looking at its value”, I can define a random variable on the value of a 6-sided die and call it . For a full definition of , I need to provide all the possible values of (what we call the random variable’s domain) and their associated probabilities. For a 6-sided die, the values are the numbers from 1 to 6; for a non-loaded die, the probabilities are all equal to
, and look at all the values it can reach with the associated probability. If my experiment is “rolling a die and looking at its value”, I can define a random variable on the value of a 6-sided die and call it . For a full definition of , I need to provide all the possible values of (what we call the random variable’s domain) and their associated probabilities. For a 6-sided die, the values are the numbers from 1 to 6; for a non-loaded die, the probabilities are all equal to  . We can write that as follows:
. We can write that as follows:
![\displaystyle \forall i \in \{1,2,3,4,5,6\}, \Pr[X = i] = \frac 1 6](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cforall+i+%5Cin+%5C%7B1%2C2%2C3%2C4%2C5%2C6%5C%7D%2C+%5CPr%5BX+%3D+i%5D+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
and read “for all  in the set of values {1,2,3,4,5,6}, the probability that takes the value equals .
in the set of values {1,2,3,4,5,6}, the probability that takes the value equals .
One of the basic ways to have an idea about the behaviour of a random variable is to look at its expectation. The expectation of a random variable can be seen as its average value, or as “suppose I roll my die 10000 times, and I average all the results (summing all the results and dividing by 10000), what result would I typically get?”
This expectation (written ![E[X]](https://s0.wp.com/latex.php?latex=E%5BX%5D&bg=eeeeee&fg=333333&s=0&c=20201002) ) can be computed with the following formula:
) can be computed with the following formula:
![E[X] = \displaystyle \sum_{i \in \text{dom}(X)} \Pr[x = i] \times i](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+%5Cdisplaystyle+%5Csum_%7Bi+%5Cin+%5Ctext%7Bdom%7D%28X%29%7D+%5CPr%5Bx+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
which can be read as “sum for all elements in the domain of of the probability that takes the value , times . In the die example, since the domain is all the integer numbers from 1 to 6, I can write
![\displaystyle \sum_{i=1}^6 \Pr[X = i] \times i](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bi%3D1%7D%5E6+%5CPr%5BX+%3D+i%5D+%5Ctimes+i&bg=eeeeee&fg=333333&s=0&c=20201002)
which I can in turn expand as follows:
![\begin{aligned}E[X] &=& 1 \times \Pr[X = 1] + 2 \times \Pr[X = 2] + 3 \times \Pr[X = 3] \\ &+& 4 \times \Pr[X = 4] + 5 \times \Pr[X = 5] + 6 \times \Pr[X = 6]\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DE%5BX%5D+%26%3D%26+1+%5Ctimes+%5CPr%5BX+%3D+1%5D+%2B+2+%5Ctimes+%5CPr%5BX+%3D+2%5D+%2B+3+%5Ctimes+%5CPr%5BX+%3D+3%5D++%5C%5C+%26%2B%26+4+%5Ctimes+%5CPr%5BX+%3D+4%5D+%2B+5+%5Ctimes+%5CPr%5BX+%3D+5%5D+%2B+6+%5Ctimes+%5CPr%5BX+%3D+6%5D%5Cend%7Baligned%7D&bg=eeeeee&fg=333333&s=0&c=20201002)
Since, for my die, all the probabilities are equal to , I can conclude with
![\displaystyle E[X] = \frac 1 6 \times (1 + 2+3+4+5+6) = \frac{21}{6} = 3.5](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%5D+%3D+%5Cfrac+1+6+%5Ctimes+%281+%2B+2%2B3%2B4%2B5%2B6%29+%3D+%5Cfrac%7B21%7D%7B6%7D+%3D+3.5&bg=eeeeee&fg=333333&s=0&c=20201002)
So the average value of a die over a large number of experiments is 3.5, as most tabletop gamers would know 😉
Now let’s look at a slightly more complicated example. Suppose that I have  dice, and that I want to know how many 6s I can expect in my dice. From a handwavy point of view, we know that we will not get an exact answer for every time we roll dice, but that we can get a rough answer. There’s no reason there should be more or less 6s than 1s, 2s, 3s, 4s or 5s, so generally speaking the dice should be distributed approximately equally in the 6 numbers, so there should be approximately
dice, and that I want to know how many 6s I can expect in my dice. From a handwavy point of view, we know that we will not get an exact answer for every time we roll dice, but that we can get a rough answer. There’s no reason there should be more or less 6s than 1s, 2s, 3s, 4s or 5s, so generally speaking the dice should be distributed approximately equally in the 6 numbers, so there should be approximately  6s over dice. (The exception to that being me playing Orks in Warhammer 40k, in which case the expected number is approximately 3 6s over 140 dice.) Let us prove that intuition properly.
6s over dice. (The exception to that being me playing Orks in Warhammer 40k, in which case the expected number is approximately 3 6s over 140 dice.) Let us prove that intuition properly.
I define  as the random variable representing the number of 6s over dice. The domain of is all the numbers from 0 to . It’s possible to compute the probability to have, for example, exactly 3 6s over dice, and even to get a general formula for
as the random variable representing the number of 6s over dice. The domain of is all the numbers from 0 to . It’s possible to compute the probability to have, for example, exactly 3 6s over dice, and even to get a general formula for  dice, but I’m way too lazy to compute all that and sum over and so on. So let’s be clever.
dice, but I’m way too lazy to compute all that and sum over and so on. So let’s be clever.
There’s a very neat trick called linearity of expectation that says that the expectation of the sum of several random variables is equal to the sum of the expectations of said random variables, which we write
![E[A + B] = E[A] + E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%2B+B%5D+%3D+E%5BA%5D+%2B+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
This is true for all random variables 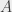 and
and 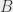 . Beware, though: it’s only true in general for the addition. We cannot say in general that
. Beware, though: it’s only true in general for the addition. We cannot say in general that ![E[A \times B] = E[A] \times E[B]](https://s0.wp.com/latex.php?latex=E%5BA+%5Ctimes+B%5D+%3D+E%5BA%5D+%5Ctimes+E%5BB%5D&bg=eeeeee&fg=333333&s=0&c=20201002) : that’s in particular true if the variables are independent, but it’s not true in general.
: that’s in particular true if the variables are independent, but it’s not true in general.
Now we’re going to define variables, called  so that is the sum of all these variables. We can define, for each variable
so that is the sum of all these variables. We can define, for each variable 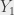 , the domain {0,1}, and we say that is equal to 1 if and only if the die number 1 shows a 6. The other variables
, the domain {0,1}, and we say that is equal to 1 if and only if the die number 1 shows a 6. The other variables  are defined similarly, one for each die. Since I have variables, which take value 1 when their associated die shows a 6, I can write
are defined similarly, one for each die. Since I have variables, which take value 1 when their associated die shows a 6, I can write

This is where I use linearity of expectation:
![\displaystyle E[Y] = E\left[\sum_{i=1}^n Y_i\right] = \sum_{i=1}^n E[Y_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY%5D+%3D+E%5Cleft%5B%5Csum_%7Bi%3D1%7D%5En+Y_i%5Cright%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D&bg=eeeeee&fg=333333&s=0&c=20201002)
The main trick here is that variables are much simpler to deal with than . With probability , they take value 1; with probability  , they take value 0. Consequently, the expectation of is also much easier to compute:
, they take value 0. Consequently, the expectation of is also much easier to compute:
![\displaystyle E[Y_i] = 1 \times \frac 1 6 + 0 \times \frac 5 6 = \frac 1 6](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY_i%5D+%3D+1+%5Ctimes+%5Cfrac+1+6+%2B+0+%5Ctimes+%5Cfrac+5+6+%3D+%5Cfrac+1+6&bg=eeeeee&fg=333333&s=0&c=20201002)
Plugging that in the previous result, we get the expectation of :
![\displaystyle E[Y] = E\left[\sum_{i=1}^n Y_i\right] = \sum_{i=1}^n E[Y_i] = \sum_{i=1}^n \frac 1 6 = \frac n 6](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BY%5D+%3D+E%5Cleft%5B%5Csum_%7Bi%3D1%7D%5En+Y_i%5Cright%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+E%5BY_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac+1+6+%3D+%5Cfrac+n+6&bg=eeeeee&fg=333333&s=0&c=20201002)
which is the result we expected.
Now my examples are pretty simple. But we can use that kind of tools in much more complicated situations. And there’s a fair amount of other tools that allow to estimate things around random variables, and to have a fairly good idea of what’s happening… even if we involve dice in the process.
Related
One thought on “Intro to probability theory – part 2”