Note: this post is a translation/adaptation of a post I wrote in French a few years ago: Intuition mathématique.
I initially wrote that post as a “warning” to my French-reading readers, saying “I might not manage to avoid annoying language tics such as ‘intuitively’, ‘obviously’, ‘it’s easy to see that'”. I think I got slightly better at that since then (or at least slightly better at noticing it and correcting it), but it’s still probably something I do.
I do try to avoid the “intuitive argument” when I explain something, because it used to make me quite anxious when I was on the receiving end of it and I had a hard time understanding why it was intuitive. But still, it does happen – it did happen in an exam once, to fail at explaining “why it’s intuitive”. Something that felt so brightly obvious that I had forgotten why it was so obvious. It’s quite annoying when someone points it out to you… especially when the “someone” is the examiner.
One of the most interesting articles I read on the topic was from Terry Tao, There’s more to mathematics than rigour and proofs. He distinguishes between three “stages” in math education:
- the “pre-rigourous stage” – you make a lot of approximations, analogies, and probably you spend more time computing than theorizing
- the “rigorous” stage – you try to do things properly, in a precise and formal way, and you work with abstract objects without necessarily having a deep understanding of what they mean (but you do work with them properly)
- the “post-rigorous stage” – you know enough of your domain to know which approximations and which analogies are indeed valid, you have a good idea fairly quickly about what something is going to yield when the proof/computation is done, and you actually understand the concepts you work with.
Six years ago, when I wrote the original version of this post, I was considering myself a mix of the three. I did start to get some “intuition” (and I’ll explain later what I meant by that), but I was still pretty bad at finishing a complex computation properly. And, obviously, it did (and still does) depends on the domain: in “my” domain, I was approximately there; if you ask me right now to solve a differential equation or to work on complicated analysis, I’m probably going to feel very pre-rigourous. I’ve been out of university for a few years now, and there’s definitely some things that have regressed, that used to be post-rigourous and are now barely rigorous anymore (or that require a lot more effort to do things in a proper way, let’s say). One of the nice things that stayed, though, is that I believe I’m far less prone to make the confusion between “pre-rigourous” and “post-rigourous” than I used to be (which got me qualified as “sloppy” on more than one occasion).
Anyway, I believe that the categories are more fluid than what Tao says, but I also believe he’s right. And that there’s no need to panic when the person in front of you says: “it’s obvious/intuitive that”: she probably just has more experience than you do. And it’s sometimes hard to explain what became, with experience, obvious. If I say “it’s obvious than 2 + 3 = 5”, we’ll probably agree on it; if I ask “yeah, but why does 2 + 3 = 5 ?”, I’ll probably get an answer, but I may have some blank stares for a few seconds. It’s a bit of a caricature, but I think it’s roughly the idea.
In the everyday language, intuition is somewhat magical, a bit of “I don’t know why, but I believe that things are this way or that way, and that this or that is going to happen”. I tend to be very wary of intuition in everyday life, because I tend to be wary about what I don’t understand. In maths, the definition is roughly the same: “I think the result is going to look like that, and I feel that if I finish the proof it’s going to work”. The main advantage of mathematical intuition is that you can check it, understand why it’s correct or why it’s wrong. In my experience, (correct) intuition (or whatever you put behind that word) comes with practice, with having seen a lot of things, with the fact of linking things to one another. I believe that what people put behind “intuition” may be linking something new (a new problem) to something you’ve already seen, and to do this correctly. It’s also a matter of pattern matching. When it comes to algorithm complexity, which is the topic of the next two posts that I’ll translate, it’s “I believe this algorithm is going to take that amount of time, because it basically the same thing as this other super-well-known-thing that’s taking that amount of time”. The thing is, the associations are not always fully conscious – you may end up seeing the result first and explain it later.
It doesn’t mean that you can never be awfully wrong. Thinking that a problem is going to take a lot of time to solve (algorithmically speaking), when there is a condition that makes it much easier. Thinking that a problem is not very hard, and realizing it’s going to take way more time than ou thought. It still happens to me, in both directions. I believe that making mistakes is actually better than the previous step, which was “but how can you even have an idea on the topic?”
I don’t know how this intuition eventually develops. I know mine was much better after a few years at ETH than it was at the beginning of it. I also know it’s somewhat worse right now than when I just graduated. It’s still enough of a flux that I still get amazed by the fact that there are things now that are completely natural to me whereas they were a complete unknown a few years ago. Conversely, it’s sometimes pretty hard to realize that you once knew how to do things, and you forgot, by lack of practice (that’s a bit of my current state with my fractal generator).
But it’s also (still) new enough that I do remember the anxiety of not understanding how things can be intuitive for some people. So, I promise: I’m going to try to avoid saying things are intuitive or obvious. But I’d like you to tell me if I err in my ways, especially if it’s a problem for you. Also, there’s a fair chance that if I say “it’s intuitive”, it’s because I’m too lazy to get into explanations that seem obvious to me (but that may not be for everyone else). So, there: I’ll try to not be lazy 🙂
(Ironically: I did hesitate translating this blog post from French because it seemed like I was only saying completely obvious things in it and that it wasn’t very interesting. My guess is – it was less obvious to me 6 years ago when I wrote it, and so it’s probably not that obvious to people who spent less time than I did thinking about that sort of things 😉 )

 , where
, where  (read “two to the power of
(read “two to the power of 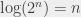

 . And, well, in the same way, I can define a logarithm that would be the inverse of this
. And, well, in the same way, I can define a logarithm that would be the inverse of this 
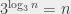

 ,
,  (because
(because  ); the logarithm base 10 of all the numbers between 10 and 100 is between 1 and 2. In the same way, you can say that the logarithm base 10 of 14578 is between 4 and 5, because 14578 is between
); the logarithm base 10 of all the numbers between 10 and 100 is between 1 and 2. In the same way, you can say that the logarithm base 10 of 14578 is between 4 and 5, because 14578 is between  and
and  , which allows to conclude on the value of the logarithm. (I’m hiding a number of things here, including the reasons that make that reasoning actually correct.)
, which allows to conclude on the value of the logarithm. (I’m hiding a number of things here, including the reasons that make that reasoning actually correct.) to
to  , and on a “normal” scale, you wouldn’t be able to distinguish between
, and on a “normal” scale, you wouldn’t be able to distinguish between  . You can however use a logarithmic scale, so that you represent with the same amount of space “things that happen between
. You can however use a logarithmic scale, so that you represent with the same amount of space “things that happen between  (corresponding to the power at which I raise
(corresponding to the power at which I raise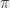 (corresponding to… okay, you get the idea) if I want to. It’s less “intuitive” than when looking at the explanation with the tree and the number of levels (because it’s pretty hard to draw
(corresponding to… okay, you get the idea) if I want to. It’s less “intuitive” than when looking at the explanation with the tree and the number of levels (because it’s pretty hard to draw  ,
, 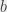 and
and  :
:
 . Here, I feel that it’s possible someone just read that and went “wait, what?”. As far as powers go, there is a “special” one: the powers of
. Here, I feel that it’s possible someone just read that and went “wait, what?”. As far as powers go, there is a “special” one: the powers of  .
.  has its own name and its own notation: it’s the exponential function, and
has its own name and its own notation: it’s the exponential function, and 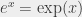 . It’s special because of an interesting property: it is equal to its derivative. And because the exponential function is often used, its inverse, the “natural logarithm” (logarithm in base
. It’s special because of an interesting property: it is equal to its derivative. And because the exponential function is often used, its inverse, the “natural logarithm” (logarithm in base  . It’s also been
. It’s also been 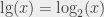 and use
and use  .
.  . Formally, we write that
. Formally, we write that

 . And you can represent the natural logarithm of any value (greater than 1) by the area of the zone between the x-axis and the
. And you can represent the natural logarithm of any value (greater than 1) by the area of the zone between the x-axis and the  for all
for all  ).
).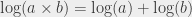
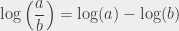
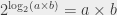
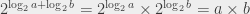
 , then
, then  , putting everything together yields the first result. The second equality (with the minuses) can be derived in exactly the same way (and left as an exercise to the reader 😉 ).
, putting everything together yields the first result. The second equality (with the minuses) can be derived in exactly the same way (and left as an exercise to the reader 😉 ).