In a previous post, I tried to explain the P vs NP problem. I gave a rough definition of the NP complexity class: NP is the class of the problems for which, for each “yes” instance, I can get convinced in polynomial time that the answer is yes by providing me with a proof that it is indeed the case. And, at the end of that post, I vaguely mentioned (without naming it) the notion of NP-complete problems.
The usual definition of a NP-complete problem is that it’s a problem which belongs to NP, and which is NP-hard. So now I need to explain what NP-hard means. Informally, it’s a problem that is at least as hard as all other problems of the NP class. Another informal way to say that is that it’s at least as hard as another NP-hard problem. The problem with that definition is the bootstrap problem: you’d need a first NP-hard problem to compare it to the others.
The archetypal NP-hard problem is SAT, which was the topic of my previous post. Since SAT is also in NP, SAT is also the archetypal NP-complete problem. It’s not a priori obvious that SAT is NP-hard. But one can prove that even 3-SAT is NP-hard, where 3-SAT represents the CNF instances of SAT where all clauses have exactly 3 literals. I’m not going to go through the proof, because that would imply that I’d explain a lot of things that I kind of don’t want to explain. For the people who are interested in the topic, it’s been proven in 1971, and it is known as the Cook-Levin theorem.
Now that we do have a NP-hard problem, we can find other ones by reduction. We reduce a NP-hard problem (for instance, 3-SAT), to another problem that we want to prove is NP-hard (call that problem A). To do that, we show that if we can solve A efficiently (that is to say, in polynomial time), then we can solve 3-SAT efficiently.
The idea of that kind of proof is to take an arbitrary instance of the NP-hard problem, and we transform it, in polynomial time, into an instance of A that allows to conclude on the original instance. Now suppose that we can solve problem A (that is to say, any instance of problem A) in polynomial time. Then we can take any instance of SAT, transform it into an instance of problem A, solve the instance of problem A, and get a conclusion. The transformation is done in polynomial time; the solving of A is in polynomial time; summing both yields again a polynomial, so we can solve any instance of SAT in polynomial time, so we can solve SAT in polynomial time. Easy.
NP-complete problems are, in a way, “complexity equivalent”: if we know how to solve one in polynomial time, then we can solve all of them in polynomial time as well, and we can solve all problems from NP in polynomial time (since NP-hard problems are at least as hard as any problem from NP). So, if we find a way to solve in polynomial time all the instances of any NP-complete problem… we proved that P = NP. And won a million dollars. And surprised a whole lot of people.
There is a large set of problems that are known to be NP-hard, or NP-complete if they are as well in NP. And there are people who look at… exotic problems, shall we say: let me give a few links for the people who are interested and may get a laugh out of it:
- The Hardness of the Lemmings Game, or Oh no, more NP-Completeness Proofs – an article that explains that Lemmings is NP-complete
- A Survey of NP-Complete Puzzles – a paper that gathers a fair amount of results of that type
- Gaming is a hard job, but someone has to do it! – talking about video games, including Boulder Dash, Doom, and Lode Runner. And Puzzle Bobble.
After this fun interlude, I’m going to give an example of reduction, so that you see that kind of proof works. I’m going to prove that the CLIQUE problem is NP-hard. It’s pretty much the basic example that everybody gives when they’re teaching that kind of things, but there must be a reason (I guess: it’s fairly easy to explain, and the reduction is also fairly easy compared to some others). What I’m explaining here is largely coming from the CLRS, that is to say the Cormen, Leiserson, Rivest and Stein, that is to say Introduction to Algorithms – that’s the reference book for A LOT of algorithms classes. (And I have a copy at home and a copy at work – you never know.)
The CLIQUE problem is described as follows: given a graph (a set of vertices and edges) 

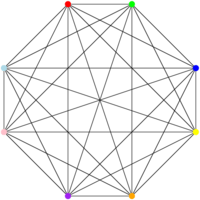
Let us reduce 3-SAT to that problem; since 3-SAT is NP-hard, CLIQUE will then be proven to be NP-hard as well. CLIQUE is in NP, because if I provide you with
To start with my reduction, I pick an arbitrary 3-SAT formula – more precisely, a 3-CNF-SAT formula (I explained the meaning of this in my post on SAT), which is a formula that has that look:
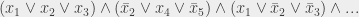
that is to say, a set of 
From there, we’re creating a graph that contains 

Then, we add edges almost everywhere. We don’t add edges in the “groups” that correspond to the clauses, and we also do not add edges between literals that are not compatible, that is to say inverse of each other. If I have two literals 

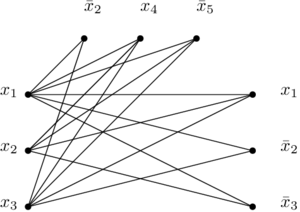
And these are the edges that are NOT in the previous graph:
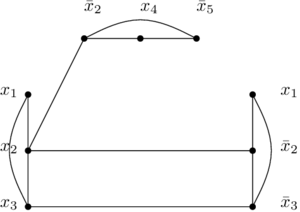
And now that we have that graph, we want to show that the SAT formula can be satisfied if and only if the graph (the first one) has a clique of size
- if the formula can be satisfied, then the graph has a clique of size
- if the graph has a clique of size
Let’s start with the first point. Suppose the formula can be satisfied. This means that we can assign a value to all the variables so that the formula is satisfied. This means that all clauses can be satisfied by this assignment. This also means that, for each clause, there’s a literal with value 1 (either a “positive” literal, for instance 

Now, let’s look at the second point: if the graph has a clique of size
So, if we can solve CLIQUE in polynomial time, then we can solve 3-SAT in polynomial time; since 3-SAT is NP-hard, CLIQUE is NP-hard, so CLIQUE is NP-complete, which concludes the proof.
Showing that a problem is NP-complete is, in a way, an indicator that the problem in question is difficult, but this needs to be mitigated a lot. For one thing, it does not say anything about a specific instance of the problem. It does not say anything about a specific subset of instances either – let me explain that. If I say that CLIQUE is difficult, it doesn’t mean that, for example, deciding whether a triangle (a clique of size 3) is in a graph is difficult. I can take all sets of 3 vertices, look at whether they form a triangle, and conclude. There are approximately 


But, in the general case, I cannot decide whether a graph over 

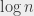

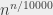

Even that does not say anything about the difficulty of a specific instance. If I’m given a graph that contains 


SAT is also NP-hard, but can solve 2-CNF-SAT instances (where all clauses contain 2 literals) in polynomial, and even linear time. There are also SAT instances that are deemed “easy”, for instance the ones that have only few dependencies between the clauses: we know that we can to solve them, and we even know how (for the people who are interested in what I mean exactly by what I mean by “a few dependencies”, I’m thinking specifically about “the ones that are in the scope of the Lovász Local Lemma“, whose application to SAT is not trivial from the Wikipedia definition, but which might be clearer here).
Generally speaking, it may even be pretty difficult to create NP-hard instances of problems that we cannot solve in polynomial time. By the way, it’s not easy to show that we don’t know how to solve a given instance in polynomial time. We can find instances problem instances that are hard (i.e. require exponential time) for a given algorithm, and easy for another algorithm…
And that’s a bit of what happens in real life: we have instance of problems for which we know that the general case is NP-hard (or worse), and that we still solve without great difficulty. It can be that the problem is “small” (it’s not a huge problem to put an exponential algorithm on a problem of size 4), but it can also be that the problem belongs to an “easy” subset of instances. Considering that an instance of a problem is hard because the general problem is hard, and giving up on it (because we won’t know how to do it) may not be a good idea – it may be that we forgot to consider an easy restriction of the problem!
As usual, “it’s not that simple”. I’ve spent a fair amount of time with theory, and I tend to look at the problems themselves more than at given instances. But it’s sometimes nice to remember that stuff that’s “theoretically hard” can end up being “practically easy” – it’s a nice change from the things that are theoretically easy but that we don’t know how to do practically… 🙂
