I recently ran into a Mastodon post of someone who started photographing all the streets of Paris, in alphabetical order: MonParisAlphabétique. I thought that it was a GREAT idea, worth pursuing for other cities, and, since I live in Zürich, I recently started AlphabeticalZurich, which I’m hosting on WordPress and Pixelfed. So if you’re only interested in the pictures and the photography side of things, you can stop reading here and go there (WordPress) or there (Pixelfed; sorted by collections/streets here).
But, there’s a few gritty details that belong to this blog rather than the other one 😉 I prefer to start projects with a tiny bit of logistics, and in particular establishing the list of streets and how to traverse it sounded like a reasonable idea. Here comes the rambling blog post about what I tried, what I played with, and what’s the current status of said logistics.
To get the list of streets of Zürich, I turned to the Swiss OpenData data, and got a link to the CSV of all the streets of Switzerland on geo.admin.ch (other formats are available and documented in the metadata).
The lines look mostly like this:
10006621;Bahnhofstrasse;8001 Zürich;261;Zürich;ZH;Street;existing;true;12.08.2023;2683111;1247210in which I’m interested in the second and third field. There’s a bit more subtlety, the third field is sometimes a multi-valued field separated by commas (when a street spans several zipcodes or even several cities).
Let’s clean this up a bit:
$ cut -d ";" -f 2,3 pure_str.csv | grep -E "8[0-9]{3} Zürich" | sortThe first few lines are kind of “meh” because they’re highways (and that sounds kind of dangerous), so let’s drop the A\d streets:
$ cut -d ";" -f 2,3 pure_str.csv | grep -E "8[0-9]{3} Zürich" | grep -v "^A[0-9]" | sort and we have a list. Now, that list contains 2425 entries, so I’m going to need to do a bit more than one street a week if I want to have a chance of finishing this. Since I know myself, I need to optimize “a bit, but not too much”. So if I’m in a street starting with A, and there’s another one in the vicinity, I may want to go shoot it while I’m at it, even if it’s technically not the next one on the list. My first idea was to use zip codes as a heuristic for “places that are in the same vicinity”. So the algorithm would look a bit like this:
pick the first non-photographed street on the alphabetical list
pick all the streets starting with the same letter in the same zipcode, in order
take pictures of all these streets, mark them as photographedOkay, this starts to be too complicated for my one-liner Bash (I tried. I really did.), so let’s get some Python instead (I did wonder if I wanted to write some ugly PHP or some ugly Python, so you’re getting some ugly Python.) I also added a bit of output to get a query for overpass turbo.
f = open('zuri_sorted.txt', 'r' )
currLett = '0'
zipStr = {}
zipList = []
for line in f.readlines():
line = line.strip()
if (not line.startswith(currLett)):
for zip in zipList:
print(zip)
print(', '.join(zipStr[zip]))
print('====')
print( '(' )
for street in zipStr[zip]:
print( 'way["name" = "', street, '"]({{bbox}});', sep='')
print(');', "out body;", ">;", "out qt;", sep="\n")
print('====')
currLett = line[0]
zipStr = {}
zipList = []
toks = line.split(';')
street = toks[0]
zips = toks[1].split(',')
visited = False
for zip in zips:
if (zip in zipStr):
zipStr[zip].append(street)
visited = True
break
if not visited:
zipStr[zips[0]] = [street]
zipList.append(zips[0])
My output for a given letter and a given zip code now looks like this:
8001 Zürich
Cäcilienstrasse, Caroline-Farner-Weg, Chorgasse
====
(
way["name" = "Cäcilienstrasse"]({{bbox}});
way["name" = "Caroline-Farner-Weg"]({{bbox}});
way["name" = "Chorgasse"]({{bbox}});
);
out body;
>;
out qt;
====I can send the part between the ==== lines to overpass turbo to see where these are on a map:
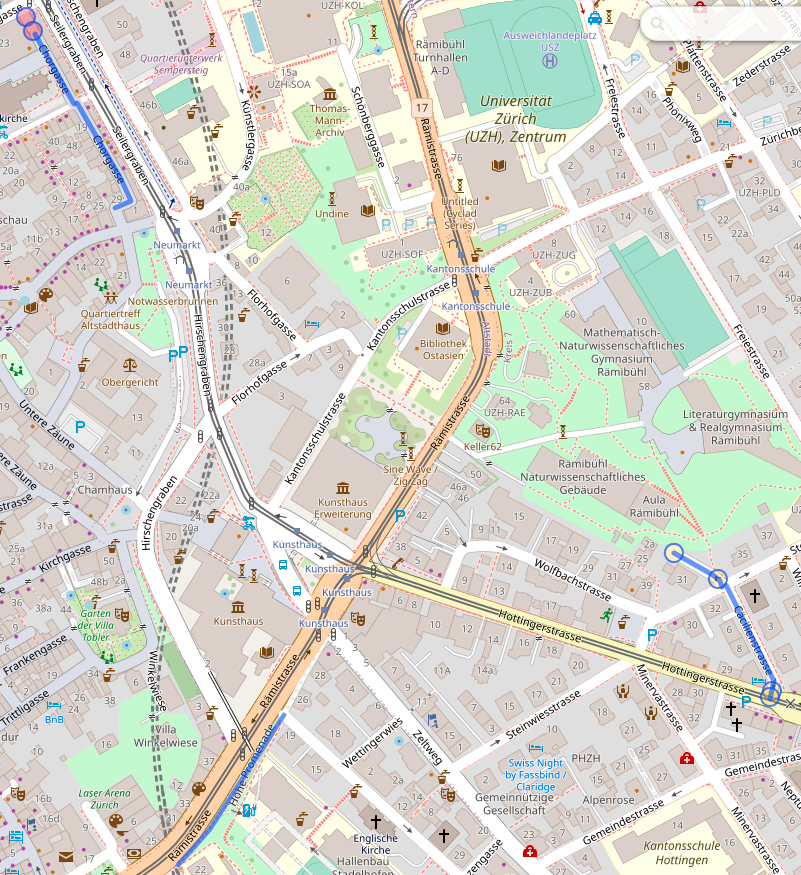
I quickly realized that this was not necessarily the best approach because a/ zipcode areas are actually quite large b/ stopping at the boundary of zipcodes is actually fairly arbitrary. But, playing with these did bring overpass turbo to my attention, including the fact that it has an API that looked useful: Overpass API. I consequently modified my query to get “streets starting with the same letter within a radius of 500m1 of a starting point”, with the starting point defined as “the first street that I haven’t processed yet”. I actually have two overpass queries now. The first one displays the map:
[out:json];
(
area[name="Zürich"][place="city"];
way(area)["name"="Aargauerstrasse"]->.a;
way(area)(around.a:500)["name" ~ "^A"][highway]({{bbox}});
);
out body;
>;
out skel qt;The second one tells me exactly which streets I’m visiting that day:
[out:csv("name";false)];
(
area[name="Zürich"][place="city"];
way(area)["name"="Aargauerstrasse"]->.a;
way(area)(around.a:500)["name" ~ "^A"][highway]({{bbox}});
for (t["name"])
(
make x name=_.val;
out;
);
);Ideally I’d be able to get both in one query somehow, and in a way that doesn’t require editing both the name of the street and its first letter in two places; for now, let’s call that good enough. Compared to the zipcode approach, I’ll also have to manually track streets and feed the next one to the query; maybe I’ll do something fancier at some point, but for now, again, let’s start things and see where the pain points are before prematurely optimizing.
There – I am now READY to go exploring the streets of Zürich! I expect the process there to be: for each street, take a picture of the street sign (to have an idea of where pictures are taken!), take a general view picture of the street, try to find a few fun details, go home, process pictures. And then, publish pictures on Wikimedia Commons, on the blog, and on Pixelfed, rinse and repeat. Oh, and update the spreadsheet, too.
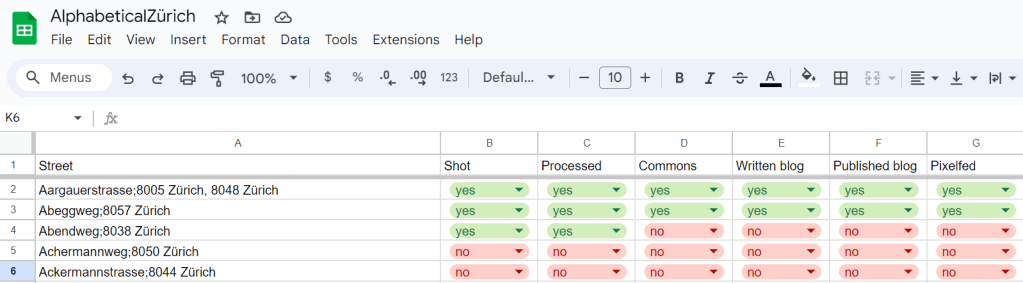
Let’s go!
- Value decided by taking the first street and see what looks reasonable from there. Very scientific approach. Also, this seems to yield 2-3km paths for photo walks, which is pretty good, actually. ↩︎
